Introdução:
Primeiramente, vamos exemplificar o nosso caso.
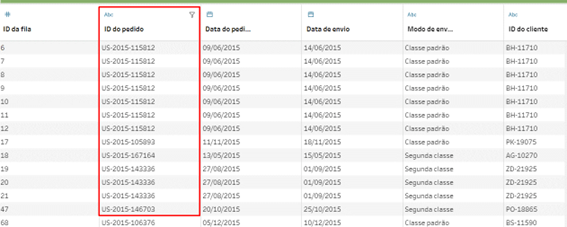
Imaginem a seguinte fonte de dados, onde temos os nossos pedidos de compra e gostaríamos de dividir o código do pedido em múltiplas linhas, uma para cada informação separada por hífen ( – ).
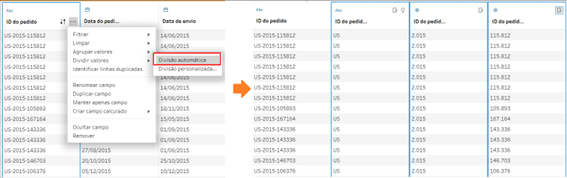
Nessa situação a solução seria simples, usamos primeiramente uma divisão condicional.
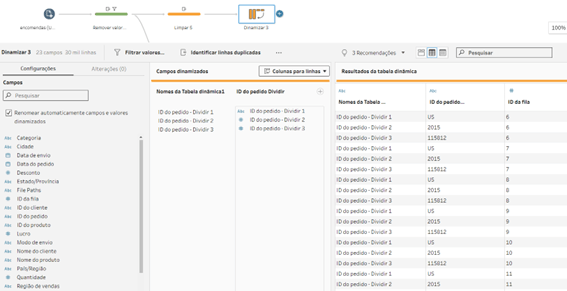
E em seguida uma ferramenta de Dinamizar com a seguinte configuração, gerando assim uma linha para cada parte do código.
Mas observem um detalhe, nesse formato ficamos presos a 3 divisões, pois ambas as etapas são dinâmicas (divisão condicional e o Dinamizar).
Se nossa base começar a apresentar novos separadores, eles precisarão identificados e ajustados dentro do fluxo para criar o campo “ID do Pedido – Dividir 4”, “ID do pedido – Dividir 5” assim sucessivamente.
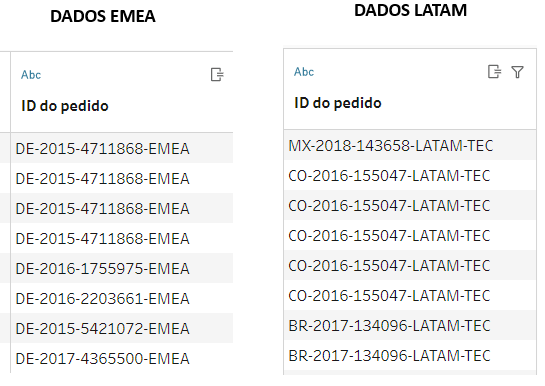
MAS NÃO TEMA, A PATH TEM A SOLUÇÃO!! Vamos incrementar um pouco mais a nossa base, agora teremos ainda mais separadores.
Passo 1: Identificando a quantidade de separadores
Para simplificar a visualização, vamos manter APENAS a coluna ID do pedido.
Vamos incluir uma etapa de limpeza e começar as tratativas.
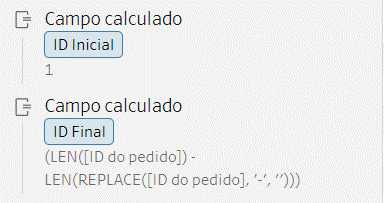
A primeira tratativa ser feita será criar 2 campos calculados, o [ID Final] e [ID inicial], onde o [ID Inicial] sempre será 1 pois teremos ao menos 1 informação presente no [ID do Pedido]. E o [ID Final] será a quantidade de separadores do Pedido.
Observem que para contar a quantidade de separadores fizemos um cálculo, esse representa a seguinte informação [O número total de caracteres da coluna] – [O número total de caracteres ao removermos o separador selecionado].
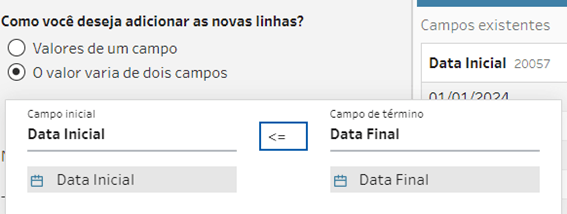
Nosso objetivo agora é criar uma linha para cada separador, para isso utilizaremos a etapa de Gerar linhas, mas vejam que essa etapa precisa de 2 DATAS para ser usada.
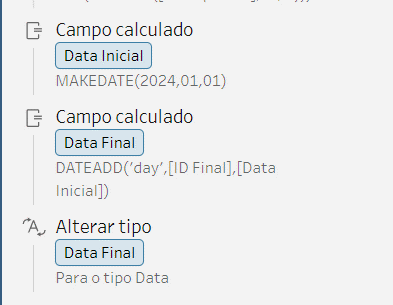
E aqui vem o pulo do gato, utilizando as colunas de ID vamos criar 2 campos calculados de data na etapa de limpeza. Onde teremos Data Inicial (essa pode ser qualquer data fixa, nessa dica vamos usar 01/01/2024), e a Data Final (essa será a nossa Data Inicial + N Dias).
E você vai se perguntar “mas o que é o N?”
O N é o nosso ID Final, a quantidade de separadores que temos, tendo assim os seguintes campos calculados
Não esqueça de alterar o tipo se for necessário.
PRONTO! Criamos a primeira parte da nossa tratativa e podemos gerar as linhas.
Passo 2: Gerando uma linha para cada separador
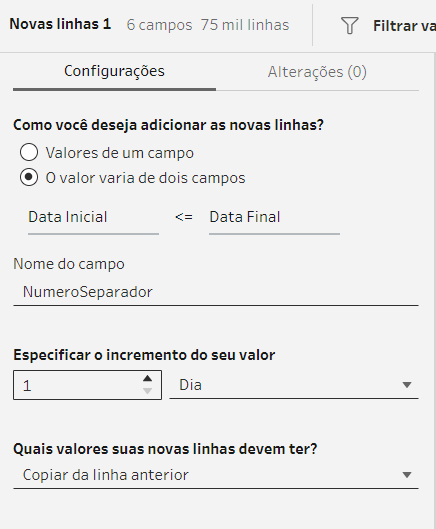
Aqui vem uma tratativa mais curta, vamos incluir uma etapa de Gerar Linhas e nela faremos a seguinte configuração.
O novo campo vai variar entre [Data Inicial] e [Data Final], ele irá se chamar [NumeroSeparador], irá incrementar 1 dia por linha e nas novas linhas geradas ele irá copiar os dados da linha anterior.
Passo 3: Fazendo a divisão dinâmica
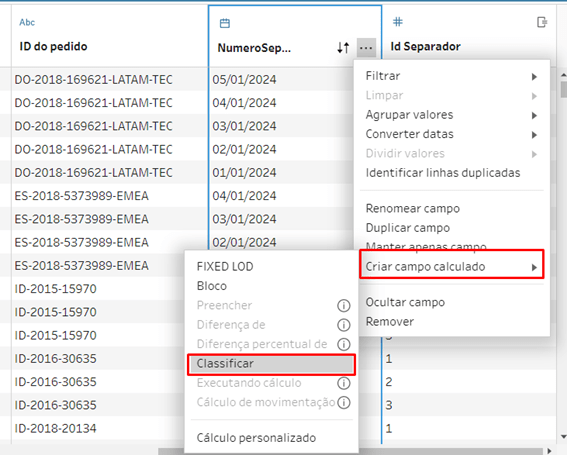
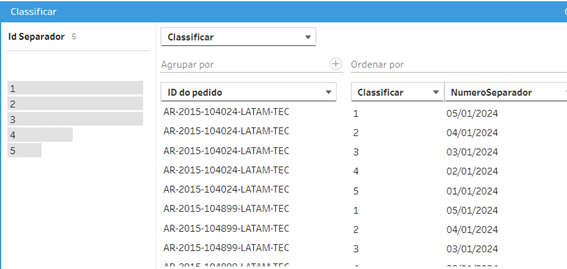
Aqui é onde todas as peças se encaixam. Vamos começar gerando um ID único para cada linha duplicada anteriormente. Para isso vamos até a nossa coluna [NumeroSeparador] e criamos um campo calculado do tipo CLASSIFICAR.
Esse campo irá se chamar [Id Separador] e iremos agrupar por ID do Pedido, classificando por Número Separador, assim teremos um identificador numérico único para cada linha de cada Pedido.
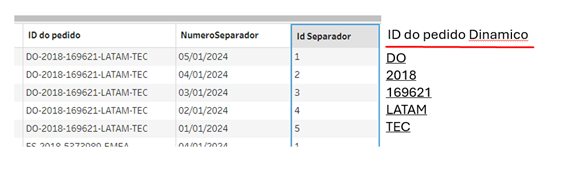
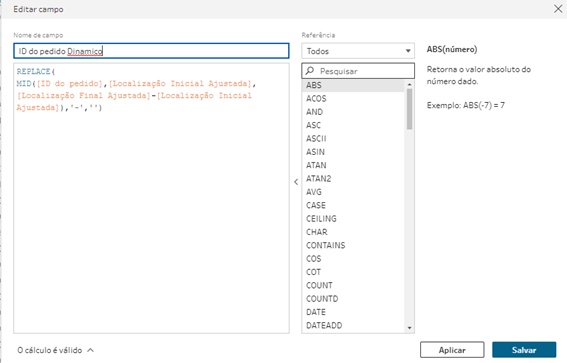
Nesse ponto poderíamos usar a fórmula de SPLIT e simplesmente configurá-la como SPLIT ([ID do pedido],’-‘,[Id Separador]), mas quando fazemos isso a base fica em branco!!! Justamente pela característica comentada no início da dica, onde a função split é estática e não consegue utilizar um campo como identificador (no caso o [Id Separador]).
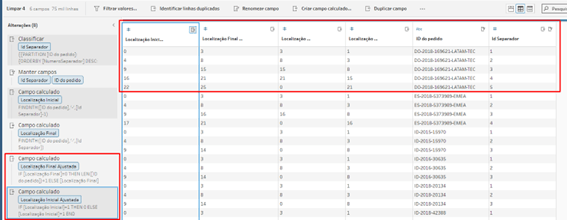
Então a solução que resta é usar a fórmula de MID onde iremos olhar para o ID do pedido e extrair apenas o que está entre os separadores, gerando assim a seguinte base
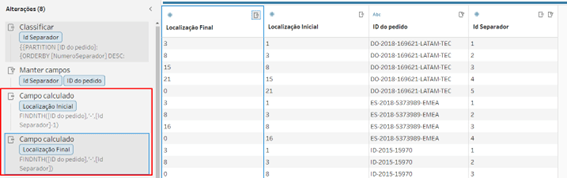
Primeiramente criamos os campos [Localização Inicial] (posição do separador anterior caso exista) e [Localização Final] (posição do próximo separador).
E precisaremos fazer mais 2 campos de apoio:
[Localização Inicial Ajustada] – Esse campo existe porque precisaremos ajustar o primeiro separador, observem que no Id Separador 1 ele diz que a localização é 1, mas na verdade deveria ser 0, pois na primeira ocorrência não existe um separador anterior, no exemplo acima seria “DO” na primeira linha.
[Localização Final Ajustada] – Pelo mesmo motivo do anterior, mas para o último separador. No Exemplo do print acima, quando chegamos ao [Id Separador] = 5 não teremos um próximo separador, nesse caso a Localização final não deveria ser 0, mas sim o tamanho completo da string+1.
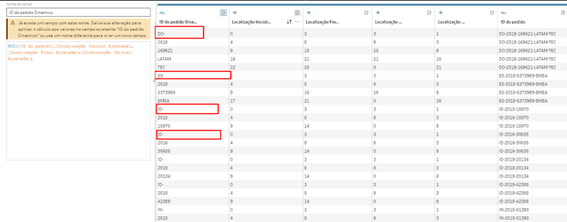
E agora vem MAIS UM pulo do gato, se aplicarmos apenas a fórmula de MID nesse momento, seria algo mais ou menos assim.
Na primeira ocorrência ainda temos o Hífen sobrando pois fazemos 3 (localização do primeiro separador) – 0 (Localização do separado inexistente da primeira linha), o correto seria retirar mais 1 caractere nesse caso específico, e aqui temos 2 opções: Ajustar os cálculos para considerar na primeira ocorrência um tamanho específico, ou simplesmente remover o hífen.
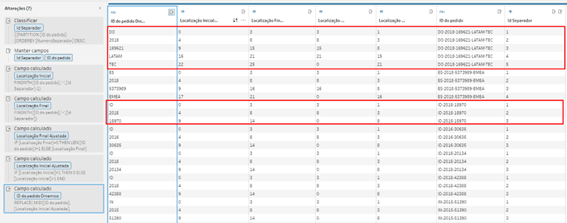
Como já estamos com muitos passos, vamos apenas remover o hífen.
Deixando nossa base final com o seguinte formato.
UFA! Conseguimos! A explicação é um pouco longa e precisamos fazer alguns macetes para chegar no resultado final, mas agora você tem um fluxo que transforma seu texto em linhas de forma dinâmica de acordo com os dados, basta reutilizá-lo de acordo com a sua base e separadores!
29 de Agosto de 2024
Pronto! Agora você sabe como criar uma Divisão Condicional dinâmica transformando texto em linhas.