Como tratar um json obtido pela ferramenta Download
O que você vai aprender?
Nesta dica você irá aprender como tratar dados que foram obtidos a partir da ferramenta download, se esses dados estiverem em formato JSON. Ao final da dica, o fluxo mostrado aqui estará disponível para download.
INTRODUÇÃO
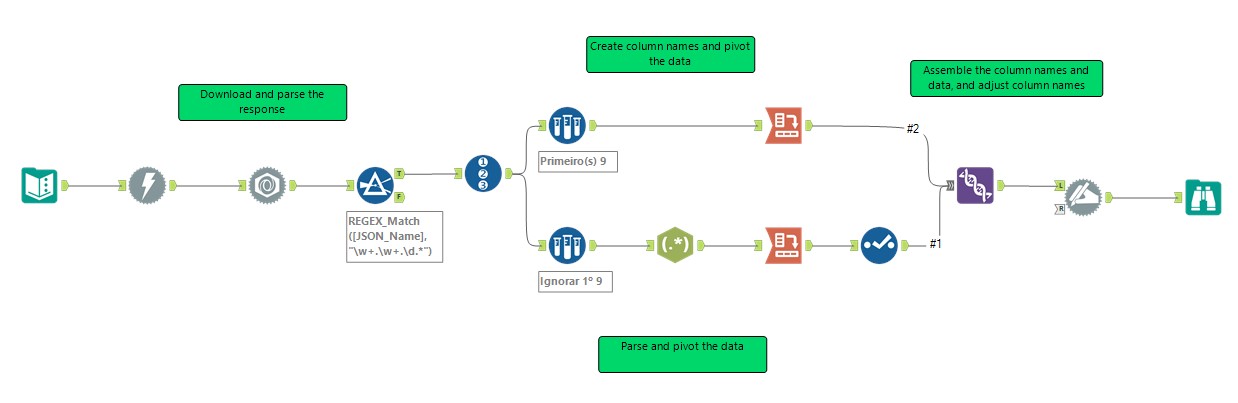
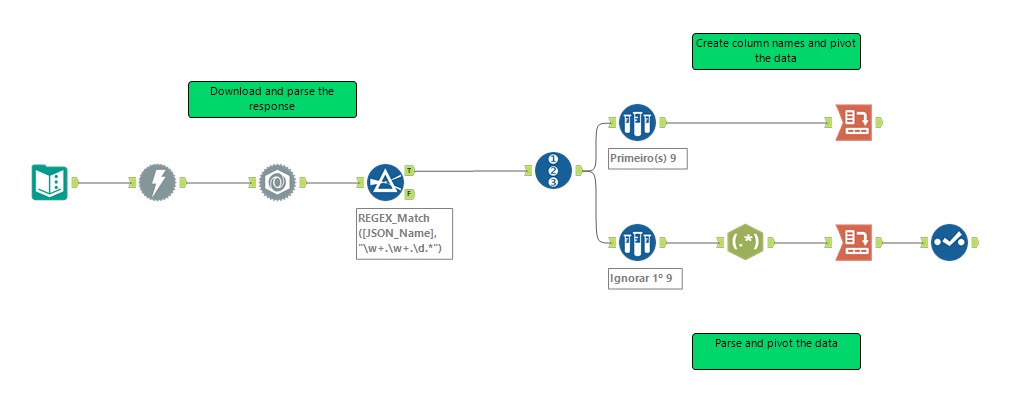
Para esta dica vamos utilizar como base o fluxo desenvolvido no Alteryx Weekly Challenge #7, mostrado abaixo:
Passo 1: Download e análise de dados
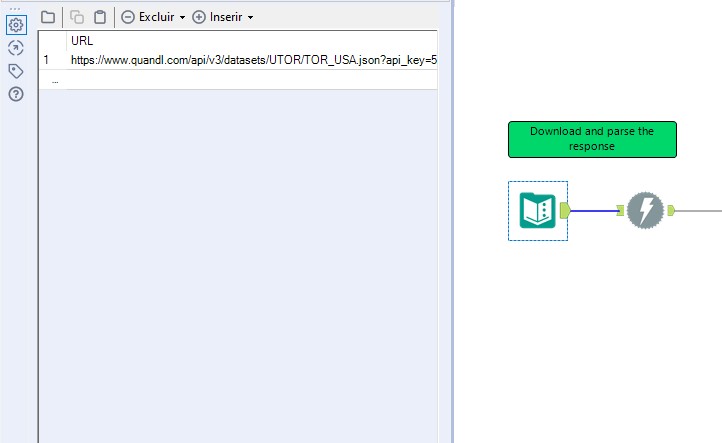
O primeiro passo é usar a ferramenta download para baixar os arquivos, então, vamos trazer uma ferramenta de entrada de texto para o workflow, e nela vamos criar um campo chamado “URL”. Nesse campo, iremos colar o URL para nosso arquivo csv.
Após isso, traga a ferramenta Download para o workflow, não é preciso alterar nenhuma configuração nela, apenas certifique-se que a opção de saída está marcada como “Cadeia de Caracteres”.
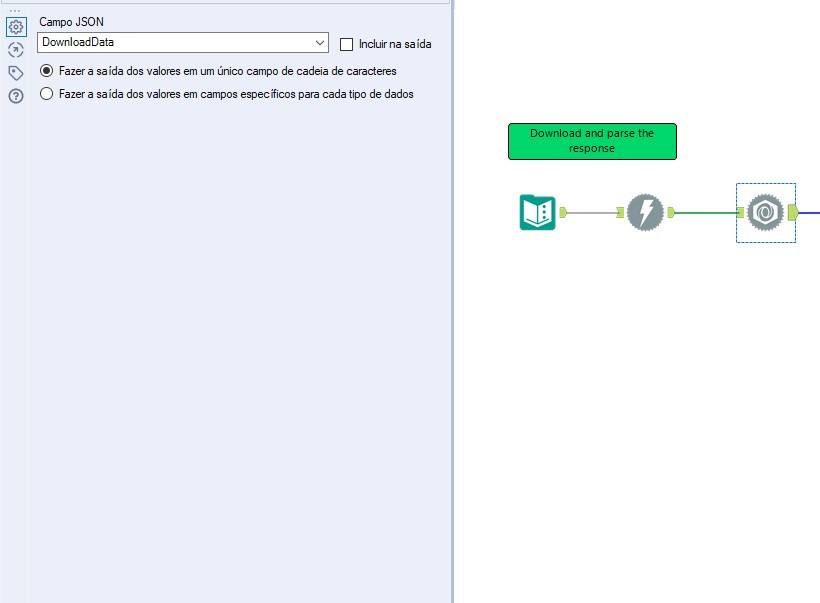
Após testar se o download de seus dados está sendo feito corretamente, precisamos adicionar uma ferramenta de Análise JSON, como mostrado abaixo:
Pode manter a configuração como mostrado na figura.
A partir desse ponto, o fluxo vai depender bastante de como os dados estarão configurados no arquivo JSON mas a linha de pensamento é parecida para todos os arquivos JSON:
Tratar os dados
Identificar nomes de colunas e fazer o pivot dos valores dos dados.
Unificar nomes de colunas com os valores.
Passo 2: Tratando dados
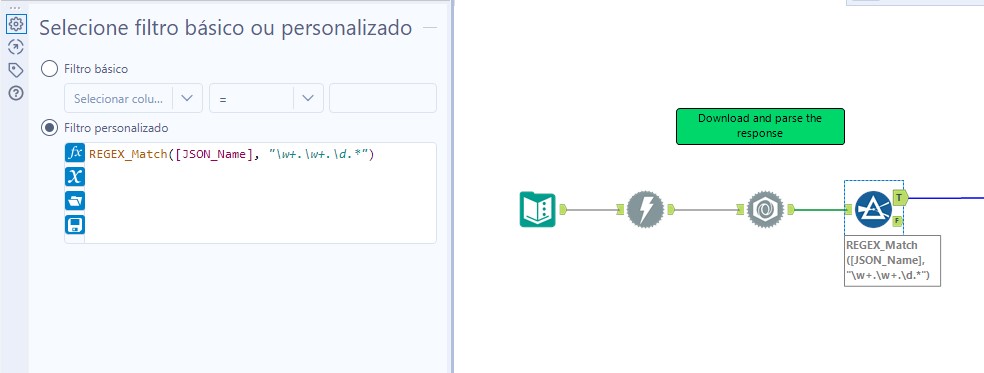
Nosso JSON veio com algumas linhas indesejadas, para retirá-las vamos inserir uma ferramenta de filtro e manter apenas as linhas que seguem a seguinte fórmula Regex: “\w+.\w+.\d.*”. Como mostrado na imagem:
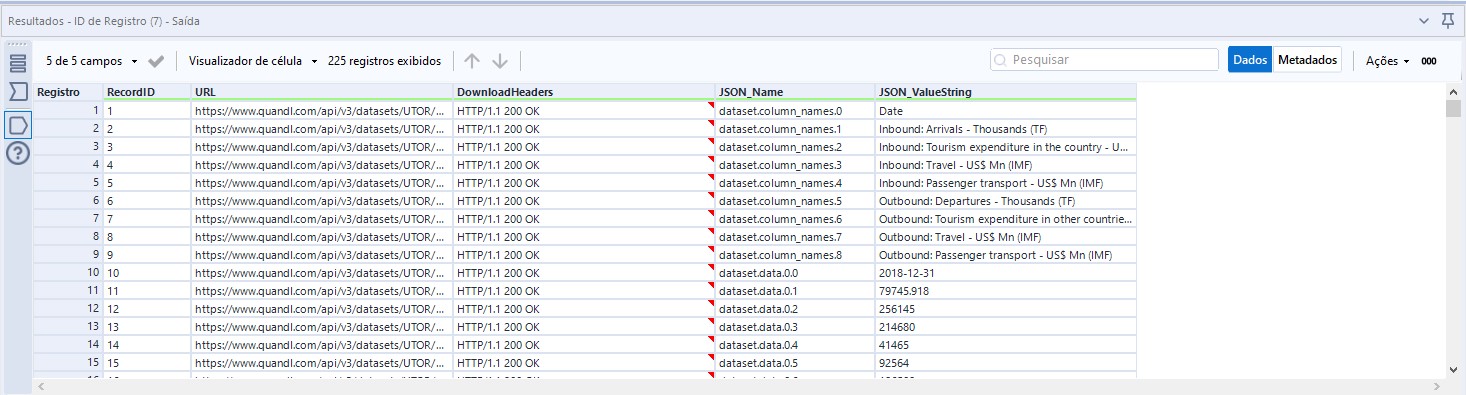
Depois, vamos adicionar uma ferramenta de ID de registro apenas para enumerar as linhas. No final dessa etapa de tratamento, nossa tabela ficará apenas com nomes das colunas e valores dos dados:
Passo 3: Identificar nomes de colunas e fazer o pivot dos valores dos dados
Após deixarmos apenas as linhas desejadas, precisamos separar os nomes de colunas e fazer o pivot dos valores dessas colunas.
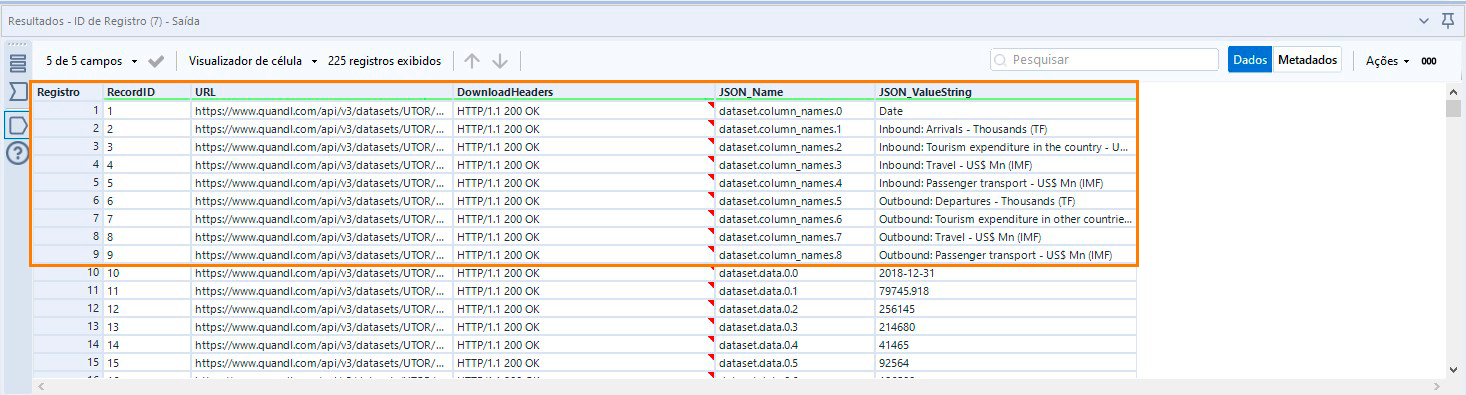
Como podemos ver na imagem anterior, nossos nomes de colunas estão nas linhas de 1 à 9:
Para separar apenas estas primeiras 9 linhas, vamos utilizar a ferramenta de Amostra, marcando a opção “Primeiras N linhas” e atribuindo N = 9.
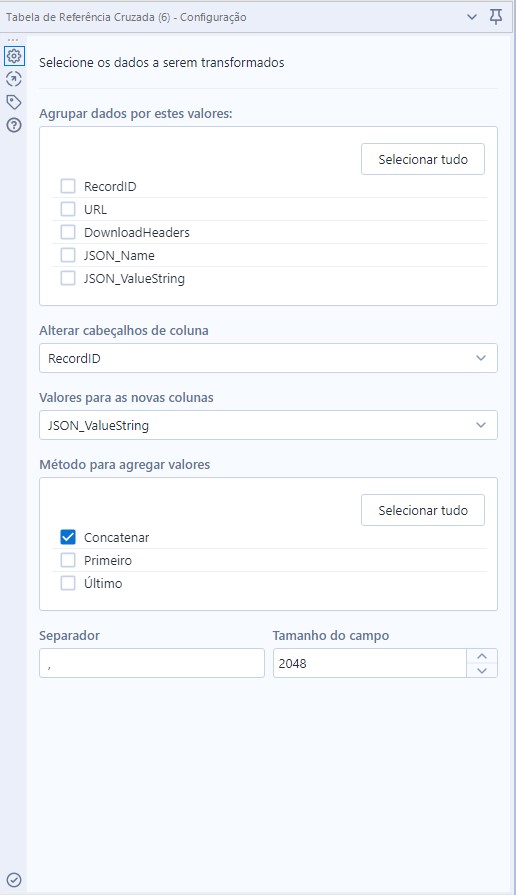
Em seguida vamos ligar ao fluxo uma ferramenta de Tabela de Referência Cruzada, ela criará 9 novas colunas e colocará os nomes de colunas (que até então estavam em 9 linhas) na primeira linha de cada coluna. Para isso, vamos usar estas configurações na ferramenta:
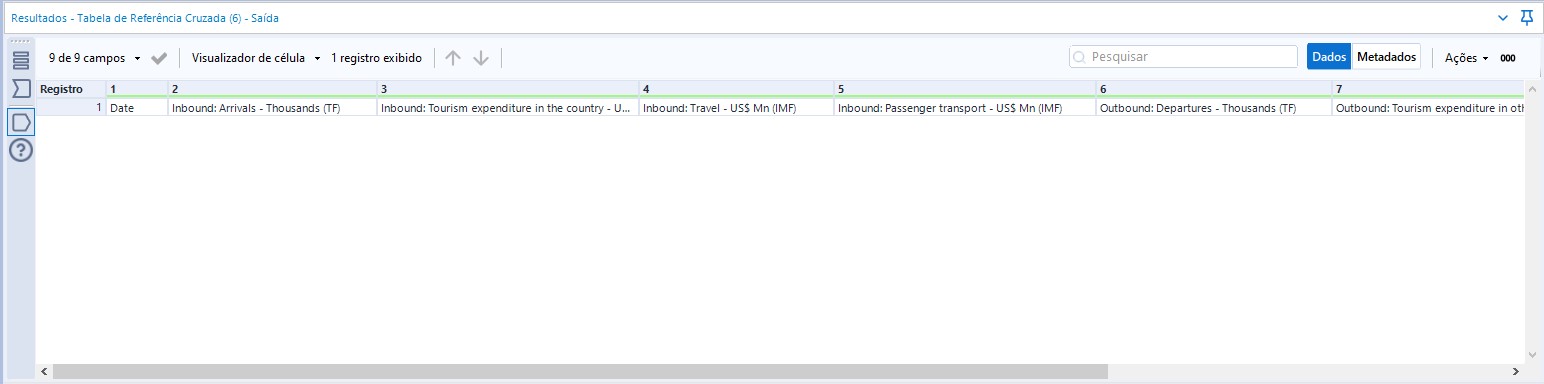
Com isso, nossos dados ficarão assim:
Após isso, devemos iniciar o processo de pivot dos valores de coluna. Vamos voltar para a ferramenta de ID de Registros e conectar a ela uma ferramenta de Amostra para pular as primeiras 9 linhas (que são os nomes das colunas). Para isso, na configuração da ferramenta de Amostra marque a opção “Ignorar as 1ªs N linhas” e atribua N = 9.
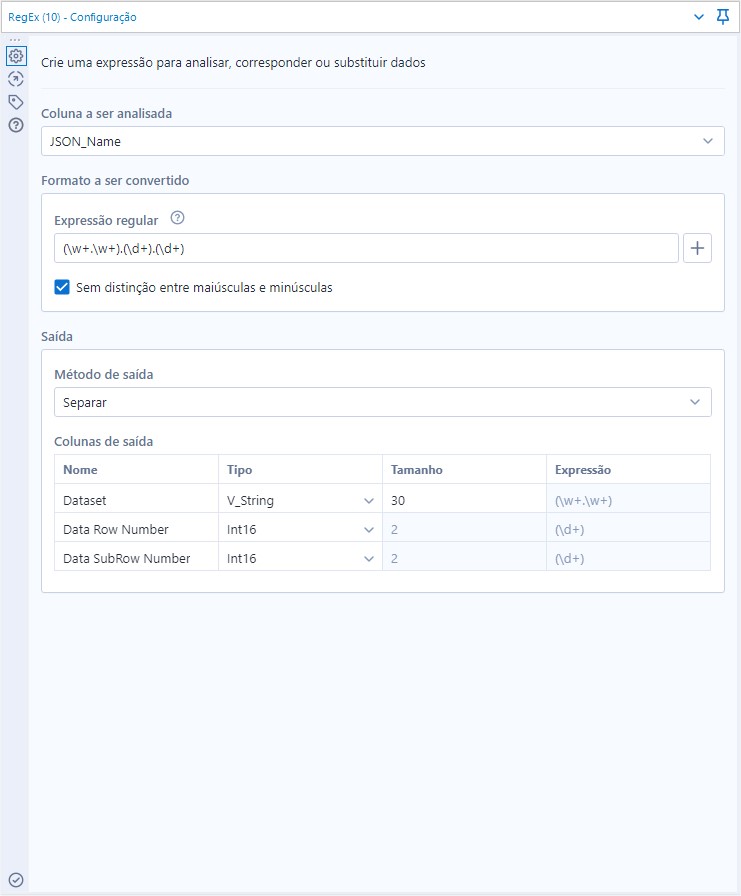
Em seguida, vamos conectar a essa nova ferramenta de Amostra uma ferramenta de RegEx. A ferramenta de RegEx servirá para quebrar os dados da coluna “JSON_Name” e, com isso, identificarmos as linhas e colunas que os dados em “JSON_ValueString” pertencerão. A expressão que usaremos na ferramenta de RegEx será esta: “(\w+.\w+).(\d+).(\d+)” e essa será sua configuração:
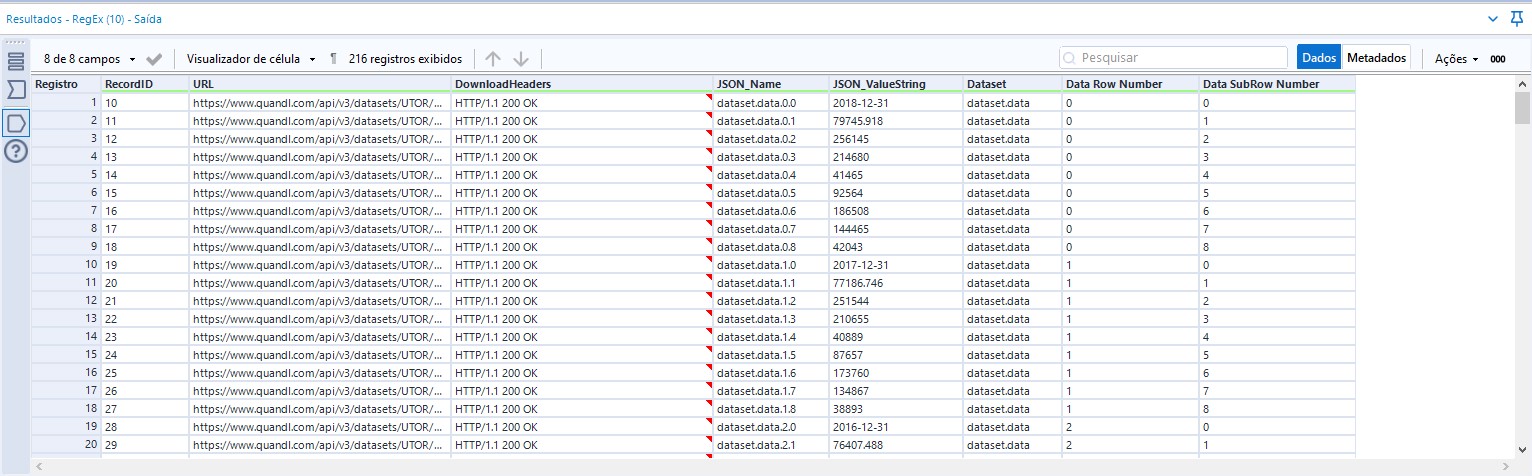
Após passarmos pela ferramenta de Regex, nossos dados ficarão assim:
Note que os dados estão seguindo uma ordem, para cada valor em “JSON_ValueString” temos um campo “Data Row Number” e “Data SubRow Number” que configuramos na ferramenta de RegEx. Esses valores representam a posição daquele dado na nova tabela.
Para cada número de “Data Row Number” existem 8 números de “Data SubRow Number”, o que significa, por exemplo, que o valor “2018-12-31” (presente na primeira linha da imagem anterior) é o dado que ficará na primeira linha e primeira coluna da nova tabela, o valor “79745.918” ficará na primeira linha e segunda coluna, e assim por diante até fechar os valores das 8 colunas para a primeira linha (Data Row Number = 0) e reiniciarmos a contagem. Quando “Data Row Number” for igual a 1, teremos os dados da segunda linha.
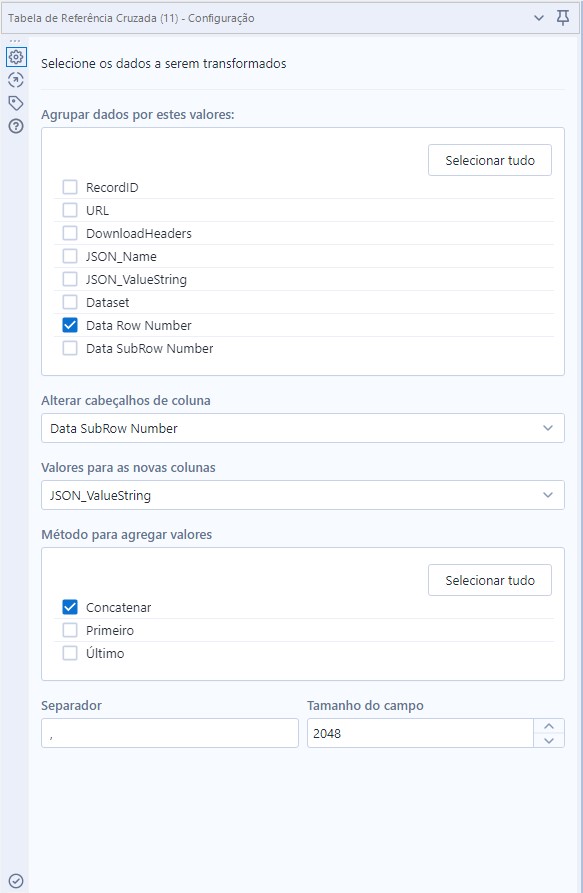
Seguindo essa lógica, iremos conectar agora uma ferramenta de Tabela de Referência Cruzada para realizar o pivot dos dados, ela terá a seguinte configuração:
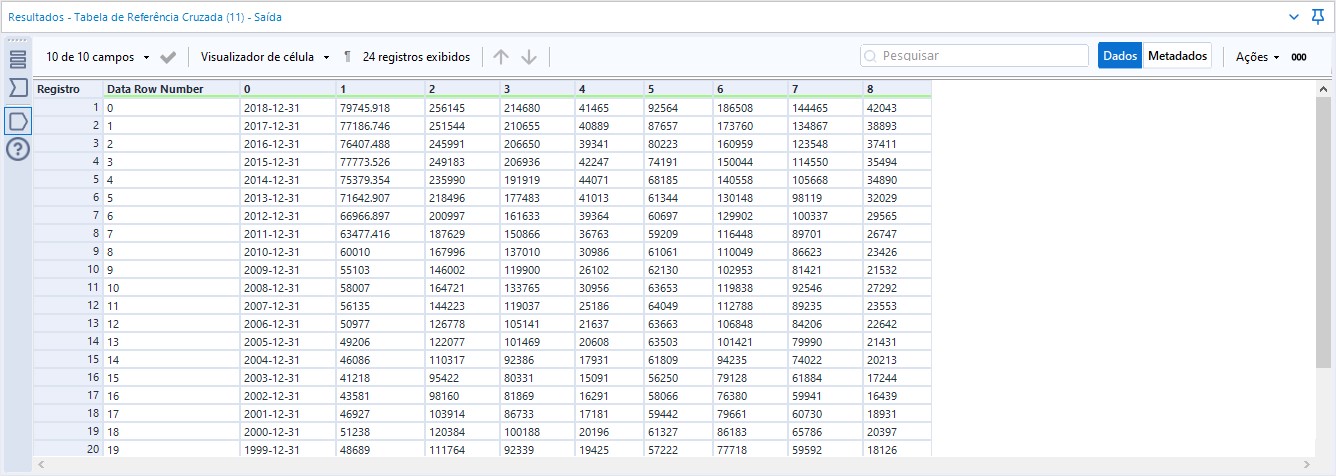
Com isso, nossos dados ficarão assim:
Após isso, vamos apenas adicionar uma ferramenta de Selecionar para retirar a coluna “Data Row Number”, já que não vamos mais usá-la. Até agora, nosso fluxo está assim:
Passo 4: Unificar nomes e valores de colunas
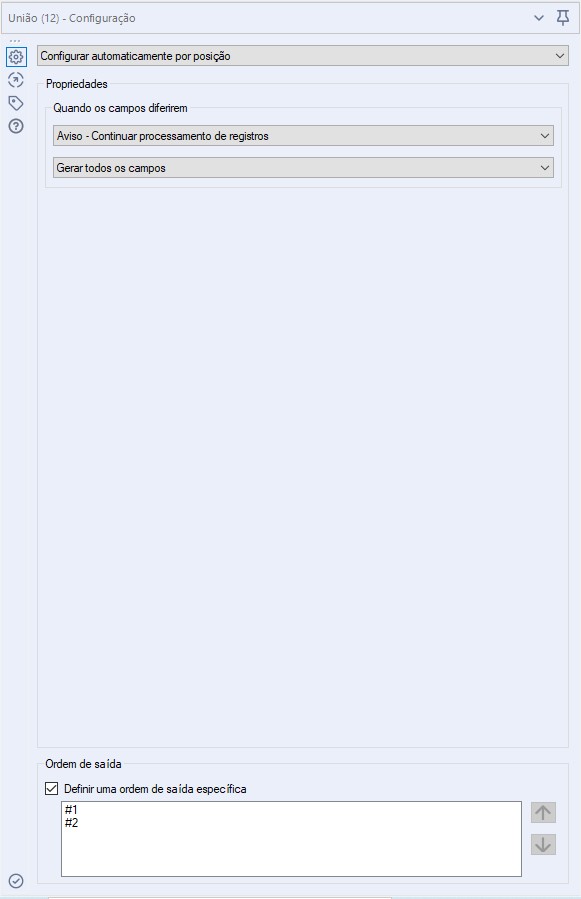
Tudo que precisamos fazer agora é unir as duas pontas do fluxo que criamos até agora, ou seja, unir os nomes das colunas com seus respectivos valores. Para isso, iremos conectar uma ferramenta de União com a seguinte configuração:
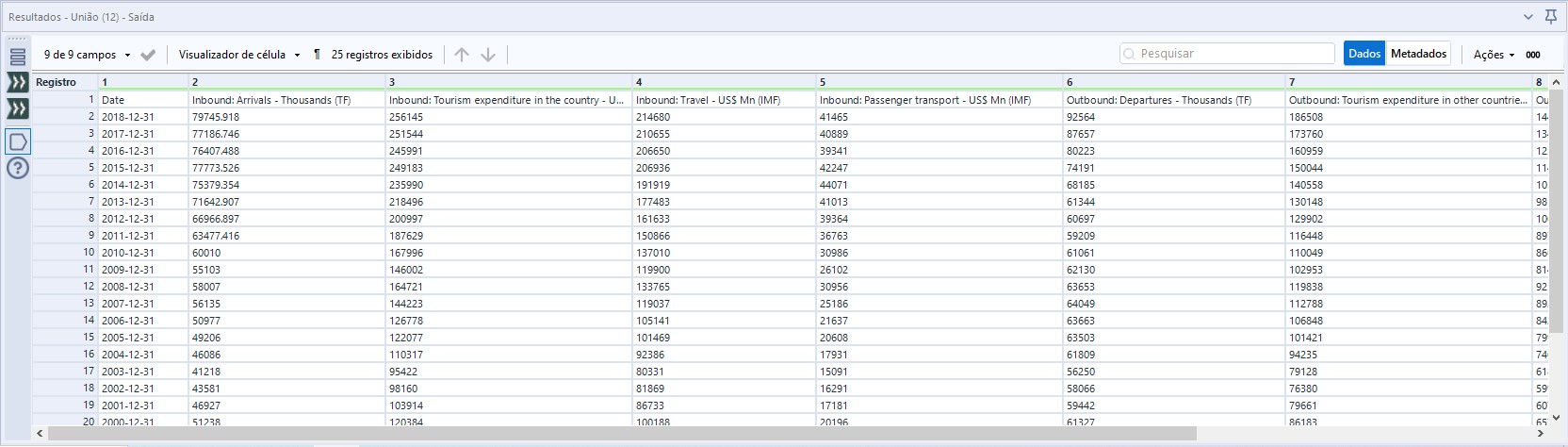
Atenção para o fato de que os nomes de coluna (a parte de cima do fluxo) devem estar primeiro na ordem de saída da união. Com isso nossos dados já unidos ficarão assim:
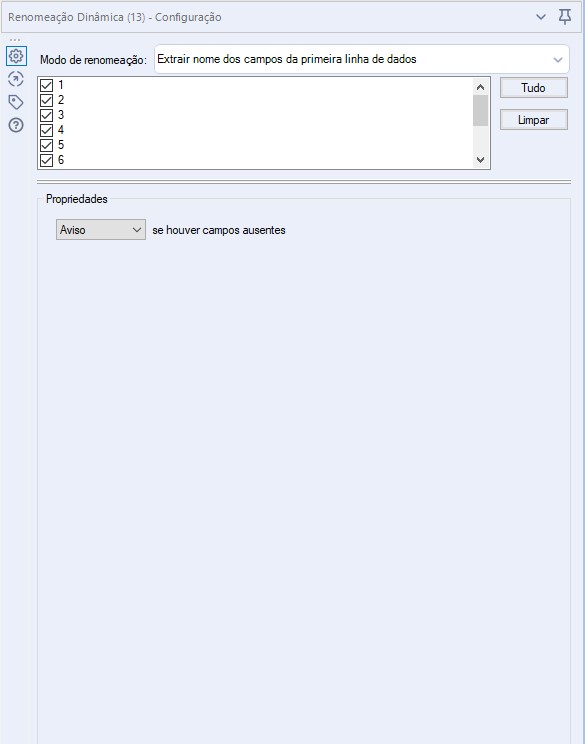
Para finalizar, precisamos apenas conectar agora uma ferramenta de Renomeação Dinâmica para transformar os dados da primeira linha em nomes de coluna, para isso a ferramenta deve ter a seguinte configuração:
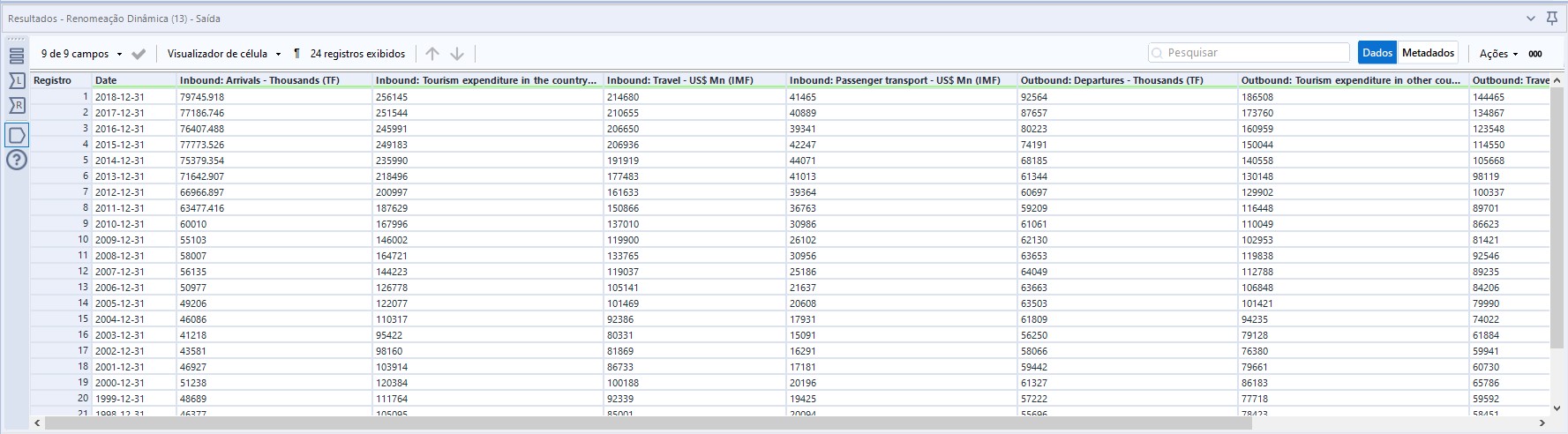
Após isso finalizamos nosso fluxo e esse é o resultado final dos nossos dados:
Você pode fazer o download desse fluxo clicando aqui.
01 de Setembro de 2021
Pronto! Agora você sabe como tratar um JSON obtido pela ferramenta Download.