
Existem situações em que precisamos compartilhar informações sensíveis ou estratégicas para terceiros, seja para desenvolver um sistema ou testar uma nova funcionalidade. Para garantir o sigilo das informações contidas neste conjunto de dados, recorremos a técnicas de descaracterização.
Nesta dica você vai aprender como fazer isso, embaralhando as informações de campos e registros.
No nosso exemplo, vamos usar um conjunto de dados com 3 campos e 10 registros. Eles estão ordenados de forma ascendente intencionalmente para que você possa comparar os dados antes e depois do processo de descaracterização.
Nosso conjunto de dados inicial é:
Nome Idade Salario
-----------------------------------
Alan 10 10000
Bernardo 20 20000
Carlos 30 30000
Daniel 40 40000
Eduardo 50 50000
Flavio 60 60000
Gilberto 70 70000
Hugo 80 80000
Ian 90 90000
Jorge 100 100000
Passo 1: Gere um fluxo para cada campo presente no seu conjunto de dados
Para cada campo, crie um fluxo independente, cada um com 2 colunas: Record ID e o campo em questão. No nosso exemplo, criaremos 3 fluxos, contendo as colunas Record ID + Nome, Record ID + Idade e Record ID + Salario, respectivamente.
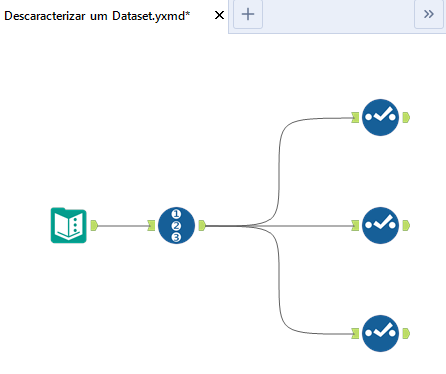
Passo 2: Crie um campo aleatório (nos 3 fluxos)
Use a ferramenta Formula para gerar um número aleatório. Ele deve ser grande o suficiente para reduzir a ocorrência de duplicidades. Existem várias maneiras de se gerar um número aleatório; a fórmula que escolhemos para este exemplo é RandInt(1000)*RandInt(1000)+RandInt(1000). Crie um novo campo e chame-o de Random.
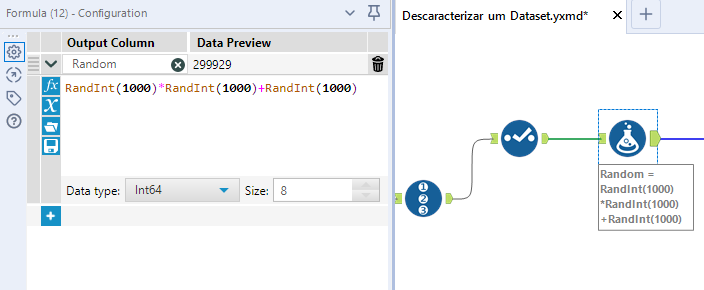
A partir desse ponto, cada passo deverá ser repetido em cada um dos fluxos. Você pode copiar e colar a ferramenta e realizar os ajustes quando necessário.
Passo 3: Ordene o conjunto de dados
Use a ferramenta Sort para ordenar o conjunto de dados pelo campo Random gerado no passo anterior.
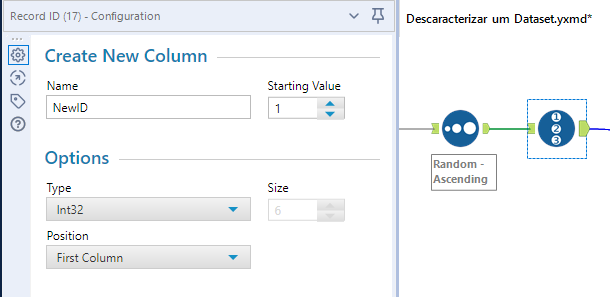
Passo 4: Crie uma nova coluna com um Sequencial
Com os dados ordenados, crie um novo índice. Chame-o de NewID.
Passo 5: Remova os campos desnecessários
Use a ferramenta Select para manter no conjunto de dados apenas o NewID e o campo próprio do fluxo. No exemplo abaixo, o campo Nome.
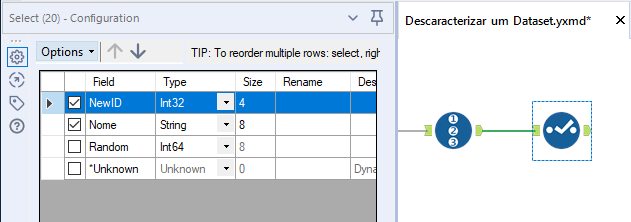
Passo 6: Una os campos novamente
Use a ferramenta Multi-Join para reagrupar os campos do seu conjunto de dados. A chave deverá ser o campo New ID.
Lembre-se que para executar este passo, as etapas anteriores devem ter sido concluídas para todos os campos.
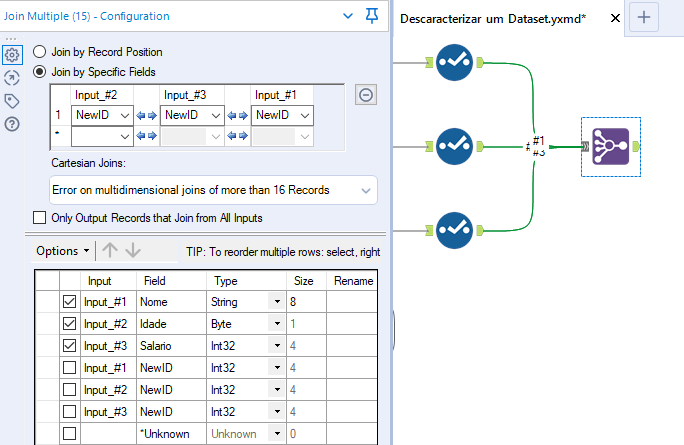
Na saída, escolha apenas os campos que fazem parte do conjunto inicial, desmarcando os campos NewID de cada entrada.
Passo 7: Verifique o resultado
Finalmente, conecte uma ferramenta Browse na saída e verifique como os dados estão embaralhados de forma aleatória.

Pronto! Agora você já sabe como usar o Alteryx para descaracterizar seus dados!